|
Revision tags: llvmorg-21-init, llvmorg-19.1.7, llvmorg-19.1.6, llvmorg-19.1.5, llvmorg-19.1.4 |
|
| #
0060c54e |
| 17-Nov-2024 |
Kazu Hirata <kazu@google.com> |
[DebugInfo] Remove unused includes (NFC) (#116551)
Identified with misc-include-cleaner.
|
|
Revision tags: llvmorg-19.1.3, llvmorg-19.1.2, llvmorg-19.1.1, llvmorg-19.1.0, llvmorg-19.1.0-rc4, llvmorg-19.1.0-rc3, llvmorg-19.1.0-rc2, llvmorg-19.1.0-rc1, llvmorg-20-init, llvmorg-18.1.8, llvmorg-18.1.7, llvmorg-18.1.6, llvmorg-18.1.5, llvmorg-18.1.4, llvmorg-18.1.3, llvmorg-18.1.2, llvmorg-18.1.1, llvmorg-18.1.0, llvmorg-18.1.0-rc4, llvmorg-18.1.0-rc3, llvmorg-18.1.0-rc2, llvmorg-18.1.0-rc1, llvmorg-19-init, llvmorg-17.0.6, llvmorg-17.0.5, llvmorg-17.0.4, llvmorg-17.0.3 |
|
| #
b8885926 |
| 11-Oct-2023 |
Kazu Hirata <kazu@google.com> |
Use llvm::endianness::{big,little,native} (NFC)
Note that llvm::support::endianness has been renamed to
llvm::endianness while becoming an enum class as opposed to an enum.
This patch replaces llvm:
Use llvm::endianness::{big,little,native} (NFC)
Note that llvm::support::endianness has been renamed to
llvm::endianness while becoming an enum class as opposed to an enum.
This patch replaces llvm::support::{big,little,native} with
llvm::endianness::{big,little,native}.
show more ...
|
| #
356139bd |
| 06-Oct-2023 |
Alexandre Ganea <37383324+aganea@users.noreply.github.com> |
[LLD][COFF] Add support for `--time-trace` (#68236)
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the p
[LLD][COFF] Add support for `--time-trace` (#68236)
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the profile trace shows in
great detail which tasks are executed.
As an example, this is what we see when linking a Unreal Engine
executable:
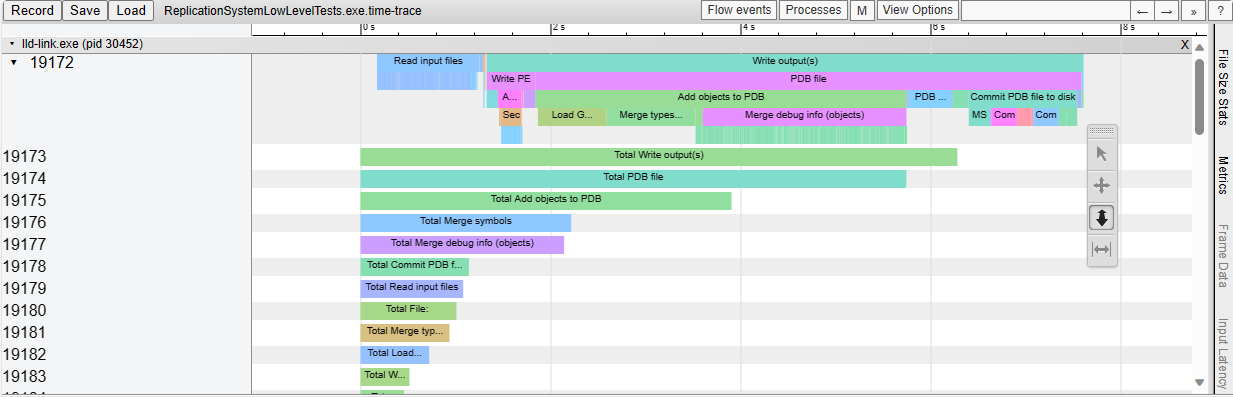
show more ...
|
|
Revision tags: llvmorg-17.0.2, llvmorg-17.0.1, llvmorg-17.0.0, llvmorg-17.0.0-rc4, llvmorg-17.0.0-rc3, llvmorg-17.0.0-rc2, llvmorg-17.0.0-rc1, llvmorg-18-init, llvmorg-16.0.6, llvmorg-16.0.5, llvmorg-16.0.4, llvmorg-16.0.3, llvmorg-16.0.2, llvmorg-16.0.1, llvmorg-16.0.0, llvmorg-16.0.0-rc4, llvmorg-16.0.0-rc3, llvmorg-16.0.0-rc2, llvmorg-16.0.0-rc1, llvmorg-17-init, llvmorg-15.0.7 |
|
| #
38818b60 |
| 04-Jan-2023 |
serge-sans-paille <sguelton@mozilla.com> |
Move from llvm::makeArrayRef to ArrayRef deduction guides - llvm/ part
Use deduction guides instead of helper functions.
The only non-automatic changes have been:
1. ArrayRef(some_uint8_pointer, 0
Move from llvm::makeArrayRef to ArrayRef deduction guides - llvm/ part
Use deduction guides instead of helper functions.
The only non-automatic changes have been:
1. ArrayRef(some_uint8_pointer, 0) needs to be changed into ArrayRef(some_uint8_pointer, (size_t)0) to avoid an ambiguous call with ArrayRef((uint8_t*), (uint8_t*))
2. CVSymbol sym(makeArrayRef(symStorage)); needed to be rewritten as CVSymbol sym{ArrayRef(symStorage)}; otherwise the compiler is confused and thinks we have a (bad) function prototype. There was a few similar situation across the codebase.
3. ADL doesn't seem to work the same for deduction-guides and functions, so at some point the llvm namespace must be explicitly stated.
4. The "reference mode" of makeArrayRef(ArrayRef<T> &) that acts as no-op is not supported (a constructor cannot achieve that).
Per reviewers' comment, some useless makeArrayRef have been removed in the process.
This is a follow-up to https://reviews.llvm.org/D140896 that introduced
the deduction guides.
Differential Revision: https://reviews.llvm.org/D140955
show more ...
|
| #
89fab98e |
| 05-Dec-2022 |
Fangrui Song <i@maskray.me> |
[DebugInfo] llvm::Optional => std::optional
https://discourse.llvm.org/t/deprecating-llvm-optional-x-hasvalue-getvalue-getvalueor/63716
|
|
Revision tags: llvmorg-15.0.6, llvmorg-15.0.5, llvmorg-15.0.4, llvmorg-15.0.3, working, llvmorg-15.0.2, llvmorg-15.0.1, llvmorg-15.0.0, llvmorg-15.0.0-rc3, llvmorg-15.0.0-rc2, llvmorg-15.0.0-rc1, llvmorg-16-init, llvmorg-14.0.6, llvmorg-14.0.5, llvmorg-14.0.4, llvmorg-14.0.3, llvmorg-14.0.2, llvmorg-14.0.1, llvmorg-14.0.0, llvmorg-14.0.0-rc4, llvmorg-14.0.0-rc3, llvmorg-14.0.0-rc2 |
|
| #
eb4c8608 |
| 19-Feb-2022 |
serge-sans-paille <sguelton@redhat.com> |
Cleanup llvm/DebugInfo/PDB headers
accumulated preprocessed size:
before: 1065515095
after: 1065629059
Discourse thread: https://discourse.llvm.org/t/include-what-you-use-include-cleanup
Differenti
Cleanup llvm/DebugInfo/PDB headers
accumulated preprocessed size:
before: 1065515095
after: 1065629059
Discourse thread: https://discourse.llvm.org/t/include-what-you-use-include-cleanup
Differential Revision: https://reviews.llvm.org/D120195
show more ...
|
|
Revision tags: llvmorg-14.0.0-rc1, llvmorg-15-init, llvmorg-13.0.1, llvmorg-13.0.1-rc3, llvmorg-13.0.1-rc2, llvmorg-13.0.1-rc1, llvmorg-13.0.0, llvmorg-13.0.0-rc4, llvmorg-13.0.0-rc3, llvmorg-13.0.0-rc2, llvmorg-13.0.0-rc1, llvmorg-14-init, llvmorg-12.0.1, llvmorg-12.0.1-rc4, llvmorg-12.0.1-rc3, llvmorg-12.0.1-rc2, llvmorg-12.0.1-rc1, llvmorg-12.0.0, llvmorg-12.0.0-rc5, llvmorg-12.0.0-rc4, llvmorg-12.0.0-rc3, llvmorg-12.0.0-rc2, llvmorg-11.1.0, llvmorg-11.1.0-rc3, llvmorg-12.0.0-rc1, llvmorg-13-init, llvmorg-11.1.0-rc2, llvmorg-11.1.0-rc1 |
|
| #
0edbc90e |
| 04-Jan-2021 |
Kazu Hirata <kazu@google.com> |
[DebugInfo] Use llvm::append_range (NFC)
|
|
Revision tags: llvmorg-11.0.1, llvmorg-11.0.1-rc2, llvmorg-11.0.1-rc1, llvmorg-11.0.0, llvmorg-11.0.0-rc6 |
|
| #
5519e4da |
| 30-Sep-2020 |
Reid Kleckner <rnk@google.com> |
Re-land "[PDB] Merge types in parallel when using ghashing"
Stored Error objects have to be checked, even if they are success
values.
This reverts commit 8d250ac3cd48d0f17f9314685a85e77895c05351.
R
Re-land "[PDB] Merge types in parallel when using ghashing"
Stored Error objects have to be checked, even if they are success
values.
This reverts commit 8d250ac3cd48d0f17f9314685a85e77895c05351.
Relands commit 49b3459930655d879b2dc190ff8fe11c38a8be5f..
Original commit message:
-----------------------------------------
This makes type merging much faster (-24% on chrome.dll) when multiple
threads are available, but it slightly increases the time to link (+10%)
when /threads:1 is passed. With only one more thread, the new type
merging is faster (-11%). The output PDB should be identical to what it
was before this change.
To give an idea, here is the /time output placed side by side:
BEFORE | AFTER
Input File Reading: 956 ms | 968 ms
Code Layout: 258 ms | 190 ms
Commit Output File: 6 ms | 7 ms
PDB Emission (Cumulative): 6691 ms | 4253 ms
Add Objects: 4341 ms | 2927 ms
Type Merging: 2814 ms | 1269 ms -55%!
Symbol Merging: 1509 ms | 1645 ms
Publics Stream Layout: 111 ms | 112 ms
TPI Stream Layout: 764 ms | 26 ms trivial
Commit to Disk: 1322 ms | 1036 ms -300ms
----------------------------------------- --------
Total Link Time: 8416 ms 5882 ms -30% overall
The main source of the additional overhead in the single-threaded case
is the need to iterate all .debug$T sections up front to check which
type records should go in the IPI stream. See fillIsItemIndexFromDebugT.
With changes to the .debug$H section, we could pre-calculate this info
and eliminate the need to do this walk up front. That should restore
single-threaded performance back to what it was before this change.
This change will cause LLD to be much more parallel than it used to, and
for users who do multiple links in parallel, it could regress
performance. However, when the user is only doing one link, it's a huge
improvement. In the future, we can use NT worker threads to avoid
oversaturating the machine with work, but for now, this is such an
improvement for the single-link use case that I think we should land
this as is.
Algorithm
----------
Before this change, we essentially used a
DenseMap<GloballyHashedType, TypeIndex> to check if a type has already
been seen, and if it hasn't been seen, insert it now and use the next
available type index for it in the destination type stream. DenseMap
does not support concurrent insertion, and even if it did, the linker
must be deterministic: it cannot produce different PDBs by using
different numbers of threads. The output type stream must be in the same
order regardless of the order of hash table insertions.
In order to create a hash table that supports concurrent insertion, the
table cells must be small enough that they can be updated atomically.
The algorithm I used for updating the table using linear probing is
described in this paper, "Concurrent Hash Tables: Fast and General(?)!":
https://dl.acm.org/doi/10.1145/3309206
The GHashCell in this change is essentially a pair of 32-bit integer
indices: <sourceIndex, typeIndex>. The sourceIndex is the index of the
TpiSource object, and it represents an input type stream. The typeIndex
is the index of the type in the stream. Together, we have something like
a ragged 2D array of ghashes, which can be looked up as:
tpiSources[tpiSrcIndex]->ghashes[typeIndex]
By using these side tables, we can omit the key data from the hash
table, and keep the table cell small. There is a cost to this: resolving
hash table collisions requires many more loads than simply looking at
the key in the same cache line as the insertion position. However, most
supported platforms should have a 64-bit CAS operation to update the
cell atomically.
To make the result of concurrent insertion deterministic, the cell
payloads must have a priority function. Defining one is pretty
straightforward: compare the two 32-bit numbers as a combined 64-bit
number. This means that types coming from inputs earlier on the command
line have a higher priority and are more likely to appear earlier in the
final PDB type stream than types from an input appearing later on the
link line.
After table insertion, the non-empty cells in the table can be copied
out of the main table and sorted by priority to determine the ordering
of the final type index stream. At this point, item and type records
must be separated, either by sorting or by splitting into two arrays,
and I chose sorting. This is why the GHashCell must contain the isItem
bit.
Once the final PDB TPI stream ordering is known, we need to compute a
mapping from source type index to PDB type index. To avoid starting over
from scratch and looking up every type again by its ghash, we save the
insertion position of every hash table insertion during the first
insertion phase. Because the table does not support rehashing, the
insertion position is stable. Using the array of insertion positions
indexed by source type index, we can replace the source type indices in
the ghash table cells with the PDB type indices.
Once the table cells have been updated to contain PDB type indices, the
mapping for each type source can be computed in parallel. Simply iterate
the list of cell positions and replace them with the PDB type index,
since the insertion positions are no longer needed.
Once we have a source to destination type index mapping for every type
source, there are no more data dependencies. We know which type records
are "unique" (not duplicates), and what their final type indices will
be. We can do the remapping in parallel, and accumulate type sizes and
type hashes in parallel by type source.
Lastly, TPI stream layout must be done serially. Accumulate all the type
records, sizes, and hashes, and add them to the PDB.
Differential Revision: https://reviews.llvm.org/D87805
show more ...
|
| #
8d250ac3 |
| 30-Sep-2020 |
Reid Kleckner <rnk@google.com> |
Revert "[PDB] Merge types in parallel when using ghashing"
This reverts commit 49b3459930655d879b2dc190ff8fe11c38a8be5f.
|
|
Revision tags: llvmorg-11.0.0-rc5, llvmorg-11.0.0-rc4, llvmorg-11.0.0-rc3, llvmorg-11.0.0-rc2, llvmorg-11.0.0-rc1, llvmorg-12-init, llvmorg-10.0.1, llvmorg-10.0.1-rc4, llvmorg-10.0.1-rc3, llvmorg-10.0.1-rc2, llvmorg-10.0.1-rc1 |
|
| #
49b34599 |
| 14-May-2020 |
Reid Kleckner <rnk@google.com> |
[PDB] Merge types in parallel when using ghashing
This makes type merging much faster (-24% on chrome.dll) when multiple
threads are available, but it slightly increases the time to link (+10%)
when
[PDB] Merge types in parallel when using ghashing
This makes type merging much faster (-24% on chrome.dll) when multiple
threads are available, but it slightly increases the time to link (+10%)
when /threads:1 is passed. With only one more thread, the new type
merging is faster (-11%). The output PDB should be identical to what it
was before this change.
To give an idea, here is the /time output placed side by side:
BEFORE | AFTER
Input File Reading: 956 ms | 968 ms
Code Layout: 258 ms | 190 ms
Commit Output File: 6 ms | 7 ms
PDB Emission (Cumulative): 6691 ms | 4253 ms
Add Objects: 4341 ms | 2927 ms
Type Merging: 2814 ms | 1269 ms -55%!
Symbol Merging: 1509 ms | 1645 ms
Publics Stream Layout: 111 ms | 112 ms
TPI Stream Layout: 764 ms | 26 ms trivial
Commit to Disk: 1322 ms | 1036 ms -300ms
----------------------------------------- --------
Total Link Time: 8416 ms 5882 ms -30% overall
The main source of the additional overhead in the single-threaded case
is the need to iterate all .debug$T sections up front to check which
type records should go in the IPI stream. See fillIsItemIndexFromDebugT.
With changes to the .debug$H section, we could pre-calculate this info
and eliminate the need to do this walk up front. That should restore
single-threaded performance back to what it was before this change.
This change will cause LLD to be much more parallel than it used to, and
for users who do multiple links in parallel, it could regress
performance. However, when the user is only doing one link, it's a huge
improvement. In the future, we can use NT worker threads to avoid
oversaturating the machine with work, but for now, this is such an
improvement for the single-link use case that I think we should land
this as is.
Algorithm
----------
Before this change, we essentially used a
DenseMap<GloballyHashedType, TypeIndex> to check if a type has already
been seen, and if it hasn't been seen, insert it now and use the next
available type index for it in the destination type stream. DenseMap
does not support concurrent insertion, and even if it did, the linker
must be deterministic: it cannot produce different PDBs by using
different numbers of threads. The output type stream must be in the same
order regardless of the order of hash table insertions.
In order to create a hash table that supports concurrent insertion, the
table cells must be small enough that they can be updated atomically.
The algorithm I used for updating the table using linear probing is
described in this paper, "Concurrent Hash Tables: Fast and General(?)!":
https://dl.acm.org/doi/10.1145/3309206
The GHashCell in this change is essentially a pair of 32-bit integer
indices: <sourceIndex, typeIndex>. The sourceIndex is the index of the
TpiSource object, and it represents an input type stream. The typeIndex
is the index of the type in the stream. Together, we have something like
a ragged 2D array of ghashes, which can be looked up as:
tpiSources[tpiSrcIndex]->ghashes[typeIndex]
By using these side tables, we can omit the key data from the hash
table, and keep the table cell small. There is a cost to this: resolving
hash table collisions requires many more loads than simply looking at
the key in the same cache line as the insertion position. However, most
supported platforms should have a 64-bit CAS operation to update the
cell atomically.
To make the result of concurrent insertion deterministic, the cell
payloads must have a priority function. Defining one is pretty
straightforward: compare the two 32-bit numbers as a combined 64-bit
number. This means that types coming from inputs earlier on the command
line have a higher priority and are more likely to appear earlier in the
final PDB type stream than types from an input appearing later on the
link line.
After table insertion, the non-empty cells in the table can be copied
out of the main table and sorted by priority to determine the ordering
of the final type index stream. At this point, item and type records
must be separated, either by sorting or by splitting into two arrays,
and I chose sorting. This is why the GHashCell must contain the isItem
bit.
Once the final PDB TPI stream ordering is known, we need to compute a
mapping from source type index to PDB type index. To avoid starting over
from scratch and looking up every type again by its ghash, we save the
insertion position of every hash table insertion during the first
insertion phase. Because the table does not support rehashing, the
insertion position is stable. Using the array of insertion positions
indexed by source type index, we can replace the source type indices in
the ghash table cells with the PDB type indices.
Once the table cells have been updated to contain PDB type indices, the
mapping for each type source can be computed in parallel. Simply iterate
the list of cell positions and replace them with the PDB type index,
since the insertion positions are no longer needed.
Once we have a source to destination type index mapping for every type
source, there are no more data dependencies. We know which type records
are "unique" (not duplicates), and what their final type indices will
be. We can do the remapping in parallel, and accumulate type sizes and
type hashes in parallel by type source.
Lastly, TPI stream layout must be done serially. Accumulate all the type
records, sizes, and hashes, and add them to the PDB.
Differential Revision: https://reviews.llvm.org/D87805
show more ...
|
|
Revision tags: llvmorg-10.0.0, llvmorg-10.0.0-rc6, llvmorg-10.0.0-rc5 |
|
| #
a7325298 |
| 13-Mar-2020 |
Alexandre Ganea <alexandre.ganea@ubisoft.com> |
[CodeView] Align type records on 4-bytes when emitting PDBs
When emitting PDBs, the TypeStreamMerger class is used to merge .debug$T records from the input .OBJ files into the output .PDB stream.
Re
[CodeView] Align type records on 4-bytes when emitting PDBs
When emitting PDBs, the TypeStreamMerger class is used to merge .debug$T records from the input .OBJ files into the output .PDB stream.
Records in .OBJs are not required to be aligned on 4-bytes, and "The Netwide Assembler 2.14" generates non-aligned records.
When compiling with -DLLVM_ENABLE_ASSERTIONS=ON, an assert was triggered in MergingTypeTableBuilder when non-ghash merging was used.
With ghash merging there was no assert.
As a result, LLD could potentially generate a non-aligned TPI stream.
We now align records on 4-bytes when record indices are remapped, in TypeStreamMerger::remapIndices().
Differential Revision: https://reviews.llvm.org/D75081
show more ...
|
|
Revision tags: llvmorg-10.0.0-rc4, llvmorg-10.0.0-rc3, llvmorg-10.0.0-rc2, llvmorg-10.0.0-rc1, llvmorg-11-init, llvmorg-9.0.1, llvmorg-9.0.1-rc3, llvmorg-9.0.1-rc2, llvmorg-9.0.1-rc1, llvmorg-9.0.0, llvmorg-9.0.0-rc6, llvmorg-9.0.0-rc5, llvmorg-9.0.0-rc4, llvmorg-9.0.0-rc3 |
|
| #
0eaee545 |
| 15-Aug-2019 |
Jonas Devlieghere <jonas@devlieghere.com> |
[llvm] Migrate llvm::make_unique to std::make_unique
Now that we've moved to C++14, we no longer need the llvm::make_unique
implementation from STLExtras.h. This patch is a mechanical replacement
of
[llvm] Migrate llvm::make_unique to std::make_unique
Now that we've moved to C++14, we no longer need the llvm::make_unique
implementation from STLExtras.h. This patch is a mechanical replacement
of (hopefully) all the llvm::make_unique instances across the monorepo.
llvm-svn: 369013
show more ...
|
|
Revision tags: llvmorg-9.0.0-rc2, llvmorg-9.0.0-rc1, llvmorg-10-init, llvmorg-8.0.1, llvmorg-8.0.1-rc4, llvmorg-8.0.1-rc3, llvmorg-8.0.1-rc2, llvmorg-8.0.1-rc1, llvmorg-8.0.0, llvmorg-8.0.0-rc5, llvmorg-8.0.0-rc4, llvmorg-8.0.0-rc3, llvmorg-7.1.0, llvmorg-7.1.0-rc1 |
|
| #
120366ed |
| 07-Feb-2019 |
Alexandre Ganea <alexandre.ganea@ubisoft.com> |
[CodeView] Fix cycles in debug info when merging Types with global hashes
When type streams with forward references were merged using GHashes, cycles
were introduced in the debug info. This was ca
[CodeView] Fix cycles in debug info when merging Types with global hashes
When type streams with forward references were merged using GHashes, cycles
were introduced in the debug info. This was caused by
GlobalTypeTableBuilder::insertRecordAs() not inserting the record on the second
pass, thus yielding an empty ArrayRef at that record slot. Later on, upon PDB
emission, TpiStreamBuilder::commit() would skip that empty record, thus
offseting all indices that came after in the stream.
This solution comes in two steps:
1. Fix the hash calculation, by doing a multiple-step resolution, iff there are
forward references in the input stream.
2. Fix merge by resolving with multiple passes, therefore moving records with
forward references at the end of the stream.
This patch also adds support for llvm-readoj --codeview-ghash.
Finally, fix dumpCodeViewMergedTypes() which previously could reference deleted
memory.
Fixes PR40221
Differential Revision: https://reviews.llvm.org/D57790
llvm-svn: 353412
show more ...
|
|
Revision tags: llvmorg-8.0.0-rc2 |
|
| #
8371da38 |
| 24-Jan-2019 |
Zachary Turner <zturner@google.com> |
[PDB] Increase TPI hash bucket count.
PDBs contain several serialized hash tables. In the microsoft-pdb
repo published to support LLVM implementing PDB support, the
provided initializes the bucket c
[PDB] Increase TPI hash bucket count.
PDBs contain several serialized hash tables. In the microsoft-pdb
repo published to support LLVM implementing PDB support, the
provided initializes the bucket count for the TPI and IPI streams
to the maximum size. This occurs in tpi.cpp L33 and tpi.cpp L398.
In the LLVM code for generating PDBs, these streams are created with
minimum number of buckets. This difference makes LLVM generated
PDBs slower for when used for debugging.
Patch by C.J. Hebert
Differential Revision: https://reviews.llvm.org/D56942
llvm-svn: 352117
show more ...
|
|
Revision tags: llvmorg-8.0.0-rc1 |
|
| #
2946cd70 |
| 19-Jan-2019 |
Chandler Carruth <chandlerc@gmail.com> |
Update the file headers across all of the LLVM projects in the monorepo
to reflect the new license.
We understand that people may be surprised that we're moving the header
entirely to discuss the ne
Update the file headers across all of the LLVM projects in the monorepo
to reflect the new license.
We understand that people may be surprised that we're moving the header
entirely to discuss the new license. We checked this carefully with the
Foundation's lawyer and we believe this is the correct approach.
Essentially, all code in the project is now made available by the LLVM
project under our new license, so you will see that the license headers
include that license only. Some of our contributors have contributed
code under our old license, and accordingly, we have retained a copy of
our old license notice in the top-level files in each project and
repository.
llvm-svn: 351636
show more ...
|
|
Revision tags: llvmorg-7.0.1, llvmorg-7.0.1-rc3, llvmorg-7.0.1-rc2, llvmorg-7.0.1-rc1, llvmorg-7.0.0, llvmorg-7.0.0-rc3, llvmorg-7.0.0-rc2, llvmorg-7.0.0-rc1, llvmorg-6.0.1, llvmorg-6.0.1-rc3, llvmorg-6.0.1-rc2, llvmorg-6.0.1-rc1, llvmorg-5.0.2, llvmorg-5.0.2-rc2, llvmorg-5.0.2-rc1, llvmorg-6.0.0, llvmorg-6.0.0-rc3, llvmorg-6.0.0-rc2, llvmorg-6.0.0-rc1 |
|
| #
0c169bf7 |
| 13-Dec-2017 |
Michael Zolotukhin <mzolotukhin@apple.com> |
Remove redundant includes from lib/DebugInfo.
llvm-svn: 320620
|
|
Revision tags: llvmorg-5.0.1, llvmorg-5.0.1-rc3, llvmorg-5.0.1-rc2, llvmorg-5.0.1-rc1, llvmorg-5.0.0, llvmorg-5.0.0-rc5, llvmorg-5.0.0-rc4, llvmorg-5.0.0-rc3, llvmorg-5.0.0-rc2, llvmorg-5.0.0-rc1, llvmorg-4.0.1, llvmorg-4.0.1-rc3 |
|
| #
5b74ff33 |
| 03-Jun-2017 |
Zachary Turner <zturner@google.com> |
[PDB] Fix use after free.
Previously MappedBlockStream owned its own BumpPtrAllocator that
it would allocate from when a read crossed a block boundary. This
way it could still return the user a con
[PDB] Fix use after free.
Previously MappedBlockStream owned its own BumpPtrAllocator that
it would allocate from when a read crossed a block boundary. This
way it could still return the user a contiguous buffer of the
requested size. However, It's not uncommon to open a stream, read
some stuff, close it, and then save the information for later.
After all, since the entire file is mapped into memory, the data
should always be available as long as the file is open.
Of course, the exception to this is when the data isn't *in* the
file, but rather in some buffer that we temporarily allocated to
present this contiguous view. And this buffer would get destroyed
as soon as the strema was closed.
The fix here is to force the user to specify the allocator, this
way it can provide an allocator that has whatever lifetime it
chooses.
Differential Revision: https://reviews.llvm.org/D33858
llvm-svn: 304623
show more ...
|
|
Revision tags: llvmorg-4.0.1-rc2 |
|
| #
8fb441ab |
| 18-May-2017 |
Zachary Turner <zturner@google.com> |
[llvm-pdbdump] Add the ability to merge PDBs.
Merging PDBs is a feature that will be used heavily by
the linker. The functionality already exists but does not
have deep test coverage because it's n
[llvm-pdbdump] Add the ability to merge PDBs.
Merging PDBs is a feature that will be used heavily by
the linker. The functionality already exists but does not
have deep test coverage because it's not easily exposed through
any tools. This patch aims to address that by adding the
ability to merge PDBs via llvm-pdbdump. It takes arbitrarily
many PDBs and outputs a single PDB.
Using this new functionality, a test is added for merging
type records. Future patches will add the ability to merge
symbol records, module information, etc.
llvm-svn: 303389
show more ...
|
| #
dd3a739d |
| 12-May-2017 |
Zachary Turner <zturner@google.com> |
[CodeView] Add a random access type visitor.
This adds a visitor that is capable of accessing type
records randomly and caching intermediate results that it
learns about during partial linear scans.
[CodeView] Add a random access type visitor.
This adds a visitor that is capable of accessing type
records randomly and caching intermediate results that it
learns about during partial linear scans. This yields
amortized O(1) access to a type stream even though type
streams cannot normally be indexed.
Differential Revision: https://reviews.llvm.org/D33009
llvm-svn: 302936
show more ...
|
|
Revision tags: llvmorg-4.0.1-rc1 |
|
| #
6e545ffc |
| 11-Apr-2017 |
Reid Kleckner <rnk@google.com> |
[PDB] Emit index/offset pairs for TPI and IPI streams
Summary:
This lets PDB readers lookup type record data by type index in O(log n)
time. It also enables makes `cvdump -t` work on PDBs produced b
[PDB] Emit index/offset pairs for TPI and IPI streams
Summary:
This lets PDB readers lookup type record data by type index in O(log n)
time. It also enables makes `cvdump -t` work on PDBs produced by LLD.
cvdump will not dump a PDB that doesn't have an index-to-offset table.
The table is sorted by type index, and has an entry every 8KB. Looking
up a type record by index is a binary search of this table, followed by
a scan of at most 8KB.
Reviewers: ruiu, zturner, inglorion
Subscribers: llvm-commits
Differential Revision: https://reviews.llvm.org/D31636
llvm-svn: 299958
show more ...
|
| #
13fc411e |
| 04-Apr-2017 |
Reid Kleckner <rnk@google.com> |
[PDB] Save one type record copy
Summary:
The TypeTableBuilder provides stable storage for type records. We don't
need to copy all of the bytes into a flat vector before adding it to the
TpiStreamBui
[PDB] Save one type record copy
Summary:
The TypeTableBuilder provides stable storage for type records. We don't
need to copy all of the bytes into a flat vector before adding it to the
TpiStreamBuilder.
This makes addTypeRecord take an ArrayRef<uint8_t> and a hash code to go
with it, which seems like a simplification.
Reviewers: ruiu, zturner, inglorion
Subscribers: llvm-commits
Differential Revision: https://reviews.llvm.org/D31634
llvm-svn: 299406
show more ...
|
|
Revision tags: llvmorg-4.0.0, llvmorg-4.0.0-rc4 |
|
| #
d9dc2829 |
| 02-Mar-2017 |
Zachary Turner <zturner@google.com> |
[Support] Move Stream library from MSF -> Support.
After several smaller patches to get most of the core improvements
finished up, this patch is a straight move and header fixup of
the source.
Diff
[Support] Move Stream library from MSF -> Support.
After several smaller patches to get most of the core improvements
finished up, this patch is a straight move and header fixup of
the source.
Differential Revision: https://reviews.llvm.org/D30266
llvm-svn: 296810
show more ...
|
|
Revision tags: llvmorg-4.0.0-rc3 |
|
| #
695ed56b |
| 28-Feb-2017 |
Zachary Turner <zturner@google.com> |
[PDB] Make streams carry their own endianness.
Before the endianness was specified on each call to read
or write of the StreamReader / StreamWriter, but in practice
it's extremely rare for streams t
[PDB] Make streams carry their own endianness.
Before the endianness was specified on each call to read
or write of the StreamReader / StreamWriter, but in practice
it's extremely rare for streams to have data encoded in
multiple different endiannesses, so we should optimize for the
99% use case.
This makes the code cleaner and more general, but otherwise
has NFC.
llvm-svn: 296415
show more ...
|
| #
120faca4 |
| 27-Feb-2017 |
Zachary Turner <zturner@google.com> |
[PDB] Partial resubmit of r296215, which improved PDB Stream Library.
This was reverted because it was breaking some builds, and
because of incorrect error code usage. Since the CL was
large and co
[PDB] Partial resubmit of r296215, which improved PDB Stream Library.
This was reverted because it was breaking some builds, and
because of incorrect error code usage. Since the CL was
large and contained many different things, I'm resubmitting
it in pieces.
This portion is NFC, and consists of:
1) Renaming classes to follow a consistent naming convention.
2) Fixing the const-ness of the interface methods.
3) Adding detailed doxygen comments.
4) Fixing a few instances of passing `const BinaryStream& X`. These
are now passed as `BinaryStreamRef X`.
llvm-svn: 296394
show more ...
|
| #
05a75e40 |
| 25-Feb-2017 |
NAKAMURA Takumi <geek4civic@gmail.com> |
Revert r296215, "[PDB] General improvements to Stream library." and followings.
r296215, "[PDB] General improvements to Stream library."
r296217, "Disable BinaryStreamTest.StreamReaderObject tempora
Revert r296215, "[PDB] General improvements to Stream library." and followings.
r296215, "[PDB] General improvements to Stream library."
r296217, "Disable BinaryStreamTest.StreamReaderObject temporarily."
r296220, "Re-enable BinaryStreamTest.StreamReaderObject."
r296244, "[PDB] Disable some tests that are breaking bots."
r296249, "Add static_cast to silence -Wc++11-narrowing."
std::errc::no_buffer_space should be used for OS-oriented errors for socket transmission.
(Seek discussions around llvm/xray.)
I could substitute s/no_buffer_space/others/g, but I revert whole them ATM.
Could we define and use LLVM errors there?
llvm-svn: 296258
show more ...
|