|
Revision tags: llvmorg-18.1.8, llvmorg-18.1.7, llvmorg-18.1.6, llvmorg-18.1.5, llvmorg-18.1.4, llvmorg-18.1.3, llvmorg-18.1.2, llvmorg-18.1.1, llvmorg-18.1.0, llvmorg-18.1.0-rc4, llvmorg-18.1.0-rc3, llvmorg-18.1.0-rc2, llvmorg-18.1.0-rc1, llvmorg-19-init, llvmorg-17.0.6, llvmorg-17.0.5, llvmorg-17.0.4, llvmorg-17.0.3 |
|
| #
356139bd |
| 06-Oct-2023 |
Alexandre Ganea <37383324+aganea@users.noreply.github.com> |
[LLD][COFF] Add support for `--time-trace` (#68236)
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the p
[LLD][COFF] Add support for `--time-trace` (#68236)
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the profile trace shows in
great detail which tasks are executed.
As an example, this is what we see when linking a Unreal Engine
executable:
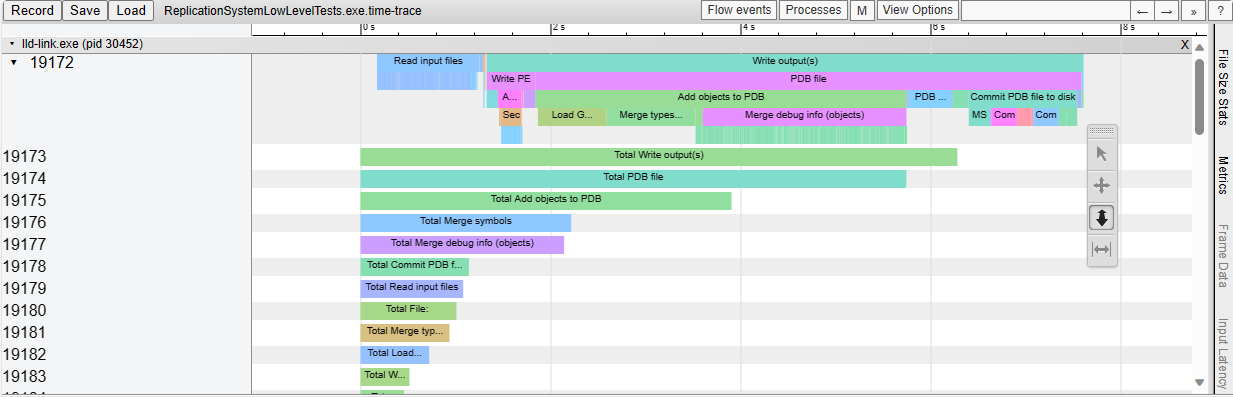
show more ...
|
|
Revision tags: llvmorg-17.0.2, llvmorg-17.0.1, llvmorg-17.0.0, llvmorg-17.0.0-rc4, llvmorg-17.0.0-rc3, llvmorg-17.0.0-rc2, llvmorg-17.0.0-rc1, llvmorg-18-init, llvmorg-16.0.6, llvmorg-16.0.5, llvmorg-16.0.4, llvmorg-16.0.3, llvmorg-16.0.2, llvmorg-16.0.1, llvmorg-16.0.0, llvmorg-16.0.0-rc4, llvmorg-16.0.0-rc3, llvmorg-16.0.0-rc2, llvmorg-16.0.0-rc1, llvmorg-17-init, llvmorg-15.0.7, llvmorg-15.0.6, llvmorg-15.0.5, llvmorg-15.0.4, llvmorg-15.0.3, working, llvmorg-15.0.2, llvmorg-15.0.1, llvmorg-15.0.0, llvmorg-15.0.0-rc3, llvmorg-15.0.0-rc2 |
|
| #
e20d210e |
| 08-Aug-2022 |
Kazu Hirata <kazu@google.com> |
[llvm] Qualify auto (NFC)
Identified with readability-qualified-auto.
|
|
Revision tags: llvmorg-15.0.0-rc1, llvmorg-16-init, llvmorg-14.0.6, llvmorg-14.0.5, llvmorg-14.0.4, llvmorg-14.0.3, llvmorg-14.0.2, llvmorg-14.0.1, llvmorg-14.0.0, llvmorg-14.0.0-rc4, llvmorg-14.0.0-rc3 |
|
| #
fbce4a78 |
| 06-Mar-2022 |
Benjamin Kramer <benny.kra@googlemail.com> |
Drop some more global std::maps. NFCI.
|
|
Revision tags: llvmorg-14.0.0-rc2, llvmorg-14.0.0-rc1, llvmorg-15-init, llvmorg-13.0.1, llvmorg-13.0.1-rc3, llvmorg-13.0.1-rc2, llvmorg-13.0.1-rc1, llvmorg-13.0.0, llvmorg-13.0.0-rc4, llvmorg-13.0.0-rc3, llvmorg-13.0.0-rc2, llvmorg-13.0.0-rc1, llvmorg-14-init, llvmorg-12.0.1, llvmorg-12.0.1-rc4, llvmorg-12.0.1-rc3, llvmorg-12.0.1-rc2, llvmorg-12.0.1-rc1, llvmorg-12.0.0, llvmorg-12.0.0-rc5, llvmorg-12.0.0-rc4, llvmorg-12.0.0-rc3, llvmorg-12.0.0-rc2, llvmorg-11.1.0, llvmorg-11.1.0-rc3, llvmorg-12.0.0-rc1, llvmorg-13-init, llvmorg-11.1.0-rc2, llvmorg-11.1.0-rc1, llvmorg-11.0.1, llvmorg-11.0.1-rc2, llvmorg-11.0.1-rc1, llvmorg-11.0.0, llvmorg-11.0.0-rc6, llvmorg-11.0.0-rc5, llvmorg-11.0.0-rc4, llvmorg-11.0.0-rc3, llvmorg-11.0.0-rc2, llvmorg-11.0.0-rc1, llvmorg-12-init, llvmorg-10.0.1, llvmorg-10.0.1-rc4, llvmorg-10.0.1-rc3, llvmorg-10.0.1-rc2, llvmorg-10.0.1-rc1, llvmorg-10.0.0, llvmorg-10.0.0-rc6, llvmorg-10.0.0-rc5, llvmorg-10.0.0-rc4, llvmorg-10.0.0-rc3, llvmorg-10.0.0-rc2, llvmorg-10.0.0-rc1, llvmorg-11-init, llvmorg-9.0.1, llvmorg-9.0.1-rc3, llvmorg-9.0.1-rc2, llvmorg-9.0.1-rc1, llvmorg-9.0.0, llvmorg-9.0.0-rc6, llvmorg-9.0.0-rc5, llvmorg-9.0.0-rc4, llvmorg-9.0.0-rc3, llvmorg-9.0.0-rc2, llvmorg-9.0.0-rc1, llvmorg-10-init |
|
| #
ac6375d9 |
| 15-Jul-2019 |
Nico Weber <nicolasweber@gmx.de> |
Expand comment about how StringsToBuckets was computed, and add more entries
The construction was explained in
https://reviews.llvm.org/D44810?id=139526#inline-391999 but reading the code
shouldn't
Expand comment about how StringsToBuckets was computed, and add more entries
The construction was explained in
https://reviews.llvm.org/D44810?id=139526#inline-391999 but reading the code
shouldn't require hunting down old reviews to understand it.
The precomputed list was missing an entry for the empty list case, and
one entry at the very end. (The current last entry is the last one where
3 * BucketCount fits in a signed int, but the reference implementation
uses unsigneds as far as I can tell, so there's room for one more entry.)
No behavior change for inputs seen in practice.
Differential Revision: https://reviews.llvm.org/D64738
llvm-svn: 366107
show more ...
|
|
Revision tags: llvmorg-8.0.1, llvmorg-8.0.1-rc4, llvmorg-8.0.1-rc3, llvmorg-8.0.1-rc2, llvmorg-8.0.1-rc1 |
|
| #
e577be4e |
| 29-Apr-2019 |
Nico Weber <nicolasweber@gmx.de> |
[PDB] Fix hash function used to write /src/headerblock
lld-link used to write PDB files that DIA couldn't recover natvis
files from if:
- The global strings table was > 64kiB
- There were at least
[PDB] Fix hash function used to write /src/headerblock
lld-link used to write PDB files that DIA couldn't recover natvis
files from if:
- The global strings table was > 64kiB
- There were at least 3 natvis files
The cause was that the hash function for the /src/headerblock stream
was incorrect: It needs to be truncated to 16 bit.
If the global strings table was <= 64kiB, truncating to 16 bit is a
no-op, so this wasn't needed for small programs.
If there are only 1 or 2 natvis files, then the growth strategy in
HashTable::grow() would mean the hash table would have 2 buckets (for 1
natvis file) or 4 buckets (for 4 natvis files), and since the hash
function is used modulo number of buckets, and since 2 and 4 divide
0x10000, the missing `% 0x10000` is a no-op there too. For 3 natvis
files, the hash table grows to 6 buckets, which has a factor that's not
common with 0x10000 and the difference starts to matter.
Fixes PR41626.
Differential Revision: https://reviews.llvm.org/D61277
llvm-svn: 359515
show more ...
|
| #
85e2cdac |
| 28-Mar-2019 |
Reid Kleckner <rnk@google.com> |
Delay initialization of three static global maps, NFC
This avoids allocating a few KB of heap memory on startup, and instead
allocates these maps lazily. I noticed this while profiling LLD.
llvm-sv
Delay initialization of three static global maps, NFC
This avoids allocating a few KB of heap memory on startup, and instead
allocates these maps lazily. I noticed this while profiling LLD.
llvm-svn: 357192
show more ...
|
|
Revision tags: llvmorg-8.0.0, llvmorg-8.0.0-rc5, llvmorg-8.0.0-rc4, llvmorg-8.0.0-rc3, llvmorg-7.1.0, llvmorg-7.1.0-rc1, llvmorg-8.0.0-rc2, llvmorg-8.0.0-rc1 |
|
| #
2946cd70 |
| 19-Jan-2019 |
Chandler Carruth <chandlerc@gmail.com> |
Update the file headers across all of the LLVM projects in the monorepo
to reflect the new license.
We understand that people may be surprised that we're moving the header
entirely to discuss the ne
Update the file headers across all of the LLVM projects in the monorepo
to reflect the new license.
We understand that people may be surprised that we're moving the header
entirely to discuss the new license. We checked this carefully with the
Foundation's lawyer and we believe this is the correct approach.
Essentially, all code in the project is now made available by the LLVM
project under our new license, so you will see that the license headers
include that license only. Some of our contributors have contributed
code under our old license, and accordingly, we have retained a copy of
our old license notice in the top-level files in each project and
repository.
llvm-svn: 351636
show more ...
|
|
Revision tags: llvmorg-7.0.1, llvmorg-7.0.1-rc3, llvmorg-7.0.1-rc2, llvmorg-7.0.1-rc1, llvmorg-7.0.0, llvmorg-7.0.0-rc3, llvmorg-7.0.0-rc2, llvmorg-7.0.0-rc1, llvmorg-6.0.1, llvmorg-6.0.1-rc3, llvmorg-6.0.1-rc2, llvmorg-6.0.1-rc1, llvmorg-5.0.2, llvmorg-5.0.2-rc2 |
|
| #
f2282762 |
| 23-Mar-2018 |
Zachary Turner <zturner@google.com> |
[PDB] Resubmit "Support embedding natvis files in PDBs."
This was reverted several times due to what ultimately turned out
to be incompatibilities in our serialized hash table format.
Several chang
[PDB] Resubmit "Support embedding natvis files in PDBs."
This was reverted several times due to what ultimately turned out
to be incompatibilities in our serialized hash table format.
Several changes went in prior to this to fix those issues since
they were more fundamental and independent of supporting injected
sources, so now that those are fixed this change should hopefully
pass.
llvm-svn: 328363
show more ...
|
| #
a6fb536e |
| 23-Mar-2018 |
Zachary Turner <zturner@google.com> |
[PDB] Make our PDBs look more like MS PDBs.
When investigating bugs in PDB generation, the first step is
often to do the same link with link.exe and then compare PDBs.
But comparing PDBs is hard be
[PDB] Make our PDBs look more like MS PDBs.
When investigating bugs in PDB generation, the first step is
often to do the same link with link.exe and then compare PDBs.
But comparing PDBs is hard because two completely different byte
sequences can both be correct, so it hampers the investigation when
you also have to spend time figuring out not just which bytes are
different, but also if the difference is meaningful.
This patch fixes a couple of cases related to string table emission,
hash table emission, and the order in which we emit strings that
makes more of our bytes the same as the bytes generated by MS PDBs.
Differential Revision: https://reviews.llvm.org/D44810
llvm-svn: 328348
show more ...
|
| #
71d36ad9 |
| 22-Mar-2018 |
Zachary Turner <zturner@google.com> |
[Codeview/PDB] Rename some methods for clarity.
NFC, this just renames some methods to better express what they
do, and also adds a few helper methods to add some symmetry to the
API in a few places
[Codeview/PDB] Rename some methods for clarity.
NFC, this just renames some methods to better express what they
do, and also adds a few helper methods to add some symmetry to the
API in a few places (for example there was a getStringFromId but not
a getIdFromString method in the string table).
llvm-svn: 328221
show more ...
|
| #
eb629994 |
| 21-Mar-2018 |
Zachary Turner <zturner@google.com> |
[PDB] Don't ignore bucket 0 when writing the PDB string table.
The hash table is a list of buckets, and the *value* stored in
the bucket cannot be 0 since that is reserved. However, the code
here w
[PDB] Don't ignore bucket 0 when writing the PDB string table.
The hash table is a list of buckets, and the *value* stored in
the bucket cannot be 0 since that is reserved. However, the code
here was incorrectly skipping over the 0'th bucket entirely.
The 0'th bucket is perfectly fine, just none of these buckets
can contain the value 0.
As a result, whenever there was a string where hash(S) % Size
was equal to 0, we would write the value in the next bucket
instead. We never caught this in our tests due to *another*
bug, which is that we would iterate the entire list of buckets
looking for the value, only using the hash value as a starting
point. However, the real algorithm stops when it finds 0 in
a bucket since it takes that to mean "the item is not in the
hash table".
The unit test is updated to carefully construct a set of hash
values that will cause one item to hash to 0 mod bucket count,
and the reader is also updated to return an error indicating that
the item is not found when it encounters a 0 bucket.
llvm-svn: 328162
show more ...
|
| #
fced5306 |
| 20-Mar-2018 |
Zachary Turner <zturner@google.com> |
Revert "Resubmit "Support embedding natvis files in PDBs.""
This is still failing on a different bot this time due to some
issue related to hashing absolute paths. Reverting until I can
figure it o
Revert "Resubmit "Support embedding natvis files in PDBs.""
This is still failing on a different bot this time due to some
issue related to hashing absolute paths. Reverting until I can
figure it out.
llvm-svn: 328014
show more ...
|
| #
132d7a13 |
| 20-Mar-2018 |
Zachary Turner <zturner@google.com> |
Resubmit "Support embedding natvis files in PDBs."
The issue causing this to fail in certain configurations
should be fixed.
It was due to the fact that DIA apparently expects there to be
a null st
Resubmit "Support embedding natvis files in PDBs."
The issue causing this to fail in certain configurations
should be fixed.
It was due to the fact that DIA apparently expects there to be
a null string at ID 1 in the string table. I'm not sure why this
is important but it seems to make a difference, so set it.
llvm-svn: 328002
show more ...
|
| #
a2155889 |
| 19-Mar-2018 |
Zachary Turner <zturner@google.com> |
Revert "Support embedding natvis files in PDBs."
This is causing a test failure on a certain bot, so I'm removing
this temporarily until we can figure out the source of the error.
llvm-svn: 327903
|
| #
de53aaf1 |
| 19-Mar-2018 |
Zachary Turner <zturner@google.com> |
Support embedding natvis files in PDBs.
Natvis is a debug language supported by Visual Studio for
specifying custom visualizers. The /NATVIS option is an
undocumented link.exe flag which will take
Support embedding natvis files in PDBs.
Natvis is a debug language supported by Visual Studio for
specifying custom visualizers. The /NATVIS option is an
undocumented link.exe flag which will take a .natvis file
and "inject" it into the PDB. This way, you can ship the
debug visualizers for a program along with the PDB, which
is very useful for postmortem debugging.
This is implemented by adding a new "named stream" to the
PDB with a special name of /src/files/<natvis file name>
and simply copying the contents of the xml into this file.
Additionally, we need to emit a single stream named
/src/headerblock which contains a hash table of embedded
files to records describing them.
This patch adds this functionality, including the /NATVIS
option to lld-link.
Differential Revision: https://reviews.llvm.org/D44328
llvm-svn: 327895
show more ...
|
|
Revision tags: llvmorg-5.0.2-rc1, llvmorg-6.0.0, llvmorg-6.0.0-rc3, llvmorg-6.0.0-rc2, llvmorg-6.0.0-rc1 |
|
| #
0c169bf7 |
| 13-Dec-2017 |
Michael Zolotukhin <mzolotukhin@apple.com> |
Remove redundant includes from lib/DebugInfo.
llvm-svn: 320620
|
|
Revision tags: llvmorg-5.0.1, llvmorg-5.0.1-rc3, llvmorg-5.0.1-rc2, llvmorg-5.0.1-rc1, llvmorg-5.0.0, llvmorg-5.0.0-rc5, llvmorg-5.0.0-rc4, llvmorg-5.0.0-rc3, llvmorg-5.0.0-rc2, llvmorg-5.0.0-rc1 |
|
| #
a8cfc29c |
| 14-Jun-2017 |
Zachary Turner <zturner@google.com> |
Resubmit "[codeview] Make obj2yaml/yaml2obj support .debug$S..."
This was originally reverted because of some non-deterministic
failures on certain buildbots. Luckily ASAN eventually caught
this as
Resubmit "[codeview] Make obj2yaml/yaml2obj support .debug$S..."
This was originally reverted because of some non-deterministic
failures on certain buildbots. Luckily ASAN eventually caught
this as a stack-use-after-scope, so the fix is included in
this patch.
llvm-svn: 305393
show more ...
|
| #
0085dce2 |
| 14-Jun-2017 |
Zachary Turner <zturner@google.com> |
Revert "[codeview] Make obj2yaml/yaml2obj support .debug$S..."
This is causing failures on linux bots with an invalid stream
read. It doesn't repro in any configuration on Windows, so
reverting unt
Revert "[codeview] Make obj2yaml/yaml2obj support .debug$S..."
This is causing failures on linux bots with an invalid stream
read. It doesn't repro in any configuration on Windows, so
reverting until I have a chance to investigate on Linux.
llvm-svn: 305371
show more ...
|
| #
a3da4467 |
| 14-Jun-2017 |
Zachary Turner <zturner@google.com> |
[codeview] Make obj2yaml/yaml2obj support .debug$S/T sections.
This allows us to use yaml2obj and obj2yaml to round-trip CodeView
symbol and type information without having to manually specify the b
[codeview] Make obj2yaml/yaml2obj support .debug$S/T sections.
This allows us to use yaml2obj and obj2yaml to round-trip CodeView
symbol and type information without having to manually specify the bytes
of the section. This makes for much easier to maintain tests. See the
tests under lld/COFF in this patch for example. Before they just said
SectionData: <blob> whereas now we can use meaningful record
descriptions. Note that it still supports the SectionData yaml field,
which could be useful for initializing a section to invalid bytes for
testing, for example.
Differential Revision: https://reviews.llvm.org/D34127
llvm-svn: 305366
show more ...
|
|
Revision tags: llvmorg-4.0.1, llvmorg-4.0.1-rc3, llvmorg-4.0.1-rc2 |
|
| #
c504ae3c |
| 03-May-2017 |
Zachary Turner <zturner@google.com> |
Resubmit r301986 and r301987 "Add codeview::StringTable"
This was reverted due to a "missing" file, but in reality
what happened was that I renamed a file, and then due to
a merge conflict both the
Resubmit r301986 and r301987 "Add codeview::StringTable"
This was reverted due to a "missing" file, but in reality
what happened was that I renamed a file, and then due to
a merge conflict both the old file and the new file got
added to the repository. This led to an unused cpp file
being in the repo and not referenced by any CMakeLists.txt
but #including a .h file that wasn't in the repo. In an
even more unfortunate coincidence, CMake didn't report the
unused cpp file because it was in a subdirectory of the
folder with the CMakeLists.txt, and not in the same directory
as any CMakeLists.txt.
The presence of the unused file was then breaking certain
tools that determine file lists by globbing rather than
by what's specified in CMakeLists.txt
In any case, the fix is to just remove the unused file from
the patch set.
llvm-svn: 302042
show more ...
|
| #
dff096f2 |
| 03-May-2017 |
Daniel Jasper <djasper@google.com> |
Revert r301986 (and subsequent r301987).
The patch is failing to add StringTableStreamBuilder.h, but that isn't
even discovered because the corresponding StringTableStreamBuilder.cpp
isn't added to
Revert r301986 (and subsequent r301987).
The patch is failing to add StringTableStreamBuilder.h, but that isn't
even discovered because the corresponding StringTableStreamBuilder.cpp
isn't added to any CMakeLists.txt file and thus never built. I think
this patch is just incomplete.
llvm-svn: 302002
show more ...
|
| #
7dba20bd |
| 02-May-2017 |
Zachary Turner <zturner@google.com> |
Make codeview::StringTable.
Previously we had knowledge of how to serialize and deserialize
a string table inside of DebugInfo/PDB, but the string table
that it serializes contains a piece that is a
Make codeview::StringTable.
Previously we had knowledge of how to serialize and deserialize
a string table inside of DebugInfo/PDB, but the string table
that it serializes contains a piece that is actually considered
CodeView and can appear outside of a PDB. We already have logic
in llvm-readobj and MCCodeView to read and write this format,
so it doesn't make sense to duplicate the logic in DebugInfoPDB
as well.
This patch makes codeview::StringTable (for writing) and
codeview::StringTableRef (for reading), updates DebugInfoPDB
to use these classes for its own writing, and updates llvm-readobj
to additionally use StringTableRef for reading.
It's a bit more difficult to get MCCodeView to use this for
writing, but it's a logical next step.
llvm-svn: 301986
show more ...
|
| #
e204a6c9 |
| 02-May-2017 |
Zachary Turner <zturner@google.com> |
Rename pdb::StringTable -> pdb::PDBStringTable.
With the forthcoming codeview::StringTable which a pdb::StringTable
would hold an instance of as one member, this ambiguity becomes
confusing. Rename
Rename pdb::StringTable -> pdb::PDBStringTable.
With the forthcoming codeview::StringTable which a pdb::StringTable
would hold an instance of as one member, this ambiguity becomes
confusing. Rename to PDBStringTable to avoid this.
llvm-svn: 301948
show more ...
|